Zen 系列 CPU 近五年多来可以说越来越香,游戏、直播、视频…… 不管什么平台什么用途,在 Intel 12 代以前基本都是首选 AMD。
先说结论,AMD CPU 上不少计算还是需要强制开 MKL 支持才更香。
1. 背景
没接触过的可能并不知道,科学计算其实是 AMD 历来挣扎的传统项目。2018 年左右有 MATLAB 用户反馈在 Zen CPU 上的运行效率奇低,还不如几年前的 Intel CPU。后来又有人挖出来 MATLAB 用的线代加速库是 Intel 出的 MKL,是 Intel 暗中给竞争对手 AMD 使绊子,在非 Intel CPU 上不开启 AVX2 指令集,降低竞争对手产品的性能…… 于是 Intel 一时遭到各路人士一致唾弃,以至于后来甚至有正义人士逆向 MKL,挖出了那个著名的环境变量 MKL_DEBUG_CPU_TYPE=5,在 Zen CPU 上强制启用 AVX2。
不过 Intel 这做法并无问题,MKL 本身不是开源软件,只支持自家产品也无可厚非。反倒是 AMD 既赚吆喝又赚买卖,却迟迟没有在软件支持上赶上对手,还要靠用户自己去“黑”着用竞争对手的 MKL,可以说很拉垮了。
事情到这本该结束了,然而没想到 2020 年 Intel 在新版本 MKL 里又暗戳戳删掉了这个环境变量,搞得一批 AMD 用户又是各种哀嚎各种降级。不过好在这个时候已经有可用的开源替代品 OpenBLAS 了,虽然某些性能还赶不上 MKL,但是也比没有加速强多了。并且从这个时候开始,NumPy 等一票计算库也渐渐向开源的 OpenBLAS 靠拢。
不过同年也有人发现 Intel 移除了 MKL 里那个变量的同时,看起来还对 Zen CPU 新增了某些运算的加速支持,也许是出于反垄断官司的考虑。同时还有人进一步逆向 MKL,还能用动态库劫持的方法强制开启对 Zen AVX/AVX2 指令集的完整支持。这个在中文圈基本上没什么人提到,原文在此查看。
Linux 上基本是这样操作的,先写个函数 fakeintel.c
int mkl_serv_intel_cpu_true() { return 1; }
编译一下
gcc -shared -fPIC -o libfakeintel.so fakeintel.c
然后使用的时候带上 LD_PRELOAD 去劫持程序,就能使用 MKL 的加速了。
LD_PRELOAD=./libfakeintel.so python test.py
2. 安装环境
首先说下我的是 2700x 的 AMD Zen+ CPU,DDR4 64GB@2933MHz 的台式。
Python 环境中要查看 blas 库信息,一般是用 numpy 带的那个打印 blas 信息的函数 np.show_config,不过实测可能并不准确。下面讲下如何正确安装链接了 mkl 的 numpy。
使用 conda 比 pip 方便不少,开启 conda-forge channel 还能有更多软件包的不同 build 可供选择,这里用 conda 举例。先创建一个新的环境叫 numpy_openblas
conda create python numpy "libblas=*=*openblas" "blas=*=*openblas" -n numpy_openblas
启用新环境,再验证下 blas
conda activate numpy_openblas
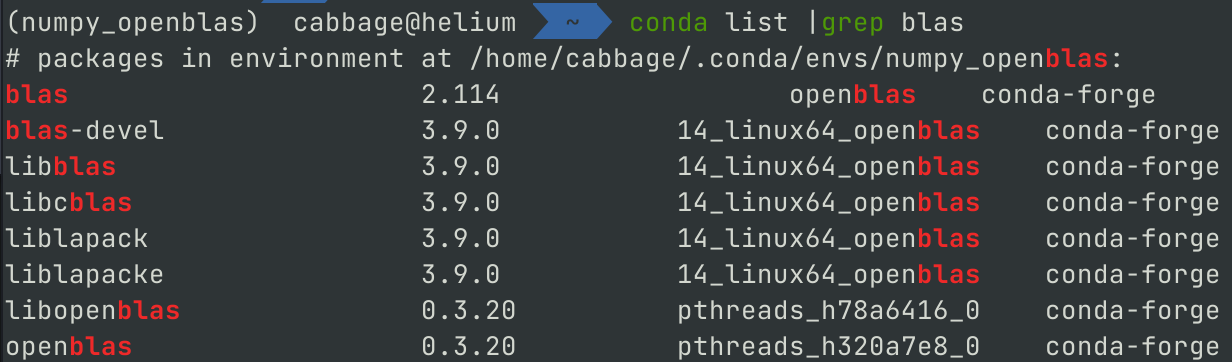
conda list | grep blas
可以看到输出软件包,已经安装使用了 openblas
但用 np.show_config() 打印出的信息并不准确:
blas_mkl_info:
libraries = ['blas', 'cblas', 'lapack', 'pthread', 'blas', 'cblas', 'lapack']
library_dirs = ['/home/cabbage/.conda/envs/numpy_openblas/lib']
define_macros = [('SCIPY_MKL_H', None), ('HAVE_CBLAS', None)]
include_dirs = ['/home/cabbage/.conda/envs/numpy_openblas/include']
blas_opt_info:
libraries = ['blas', 'cblas', 'lapack', 'pthread', 'blas', 'cblas', 'lapack', 'blas', 'cblas', 'lapack']
library_dirs = ['/home/cabbage/.conda/envs/numpy_openblas/lib']
define_macros = [('SCIPY_MKL_H', None), ('HAVE_CBLAS', None)]
include_dirs = ['/home/cabbage/.conda/envs/numpy_openblas/include']
lapack_mkl_info:
libraries = ['blas', 'cblas', 'lapack', 'pthread', 'blas', 'cblas', 'lapack']
library_dirs = ['/home/cabbage/.conda/envs/numpy_openblas/lib']
define_macros = [('SCIPY_MKL_H', None), ('HAVE_CBLAS', None)]
include_dirs = ['/home/cabbage/.conda/envs/numpy_openblas/include']
lapack_opt_info:
libraries = ['blas', 'cblas', 'lapack', 'pthread', 'blas', 'cblas', 'lapack', 'blas', 'cblas', 'lapack']
library_dirs = ['/home/cabbage/.conda/envs/numpy_openblas/lib']
define_macros = [('SCIPY_MKL_H', None), ('HAVE_CBLAS', None)]
include_dirs = ['/home/cabbage/.conda/envs/numpy_openblas/include']
挖了下发现 conda 这里安装完 openblas 是软链到了 cblas 上,猜测和这个有关系。但是不管怎么样,后面跑测试对比下测试就都清楚了。
接着另外再建个环境,安装 mkl 的 numpy:
conda deactivate
conda create python numpy "libblas=*=*mkl" "blas=*=*mkl" -n numpy_mkl
conda activate numpy_mkl
检查下 conda list | grep blas 应该是 mkl 了:

3. 测试用的代码
import numpy as np
from time import time
#print('Numpy config:')
#np.show_config()
# 生成测试数据,控制变量,非随机
np.random.seed(0)
size = 4096
A, B = np.random.random((size, size)), np.random.random((size, size))
C, D = np.random.random((size * 128,)), np.random.random((size * 128,))
E = np.random.random((size // 2, size // 4))
F = G = np.random.random((size // 2, size // 2))
F = np.dot(F, F.T)
# 矩阵点乘
def dot(N=20):
t = time()
for i in range(N):
np.dot(A, B)
print(f'点乘两个 {size}x{size} 矩阵 {N} 次,平均用时 {(time() - t) / N} 秒')
# 向量乘法
def v_dot(N=5000):
t = time()
for i in range(N):
np.dot(C, D)
print(f'点乘两个 {size * 128} 向量 {N} 次,平均用时 {(time() - t) / N * 1000} 毫秒')
# 奇异值分解
def svd(N=3):
t = time()
for i in range(N):
np.linalg.svd(E, full_matrices=False)
print(f'分解一个 {size // 2}x{size // 4} 矩阵的奇异值 {N} 次,平均用时 {(time() - t) / N} 秒')
# 科列斯基分解
def cholesky(N=3):
t = time()
for i in range(N):
np.linalg.cholesky(F)
print(f'对一个 {size // 2}x{size // 2} 矩阵科列斯基分解 {N} 次,平均用时 {(time() - t) / N} 秒')
# 特征分解
def eig(N=3):
t = time()
for i in range(N):
np.linalg.eig(G)
print(f'对一个 {size // 2}x{size // 2} 矩阵分解特征值 {N} 次,平均用时 {(time() - t) / N} 秒')
if __name__ == '__main__':
dot()
v_dot()
svd()
cholesky()
eig()
4. 运行各 blas 库的 numpy 测试
我的环境是 2700x 的 AMD Zen+ CPU,64GB@2933MHz DDR4 的台式。
-
使用 OpenBLAS 的 numpy
conda activate numpy_openblas python test.py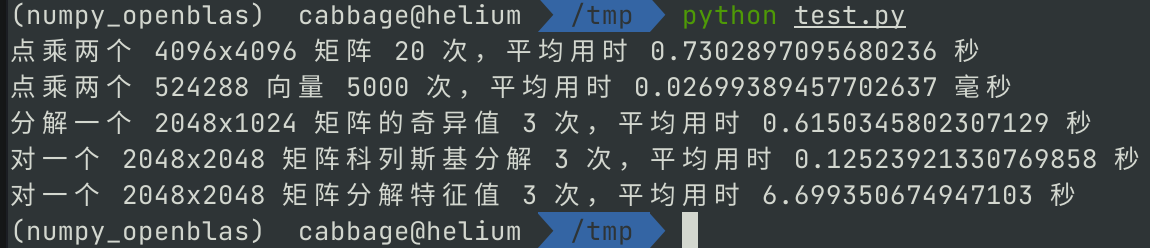
-
mkl 的 numpy,不强制开启完整支持
conda activate numpy_mkl python test.py
-
mkl 的 numpy,用上边提到动态库劫持的方法强制开启完整支持
conda activate numpy_mkl LD_PRELOAD=./libfakeintel.so python test.py
5. 结论
根据这里的测试来看,Intel MKL 仍然对 AMD CPU 有不少劣化,并且强开的 MKL 性能仍然比 OpenBLAS 好不少。至少在这里 Zen+ 的 2700x CPU 上,这个结论是很明显的了。